#P11087. [ROI 2019] 考古 (Day 2)
-
ID: 10374
Type: RemoteJudge
5000ms
1024MiB
Tried: 0
Accepted: 0
Difficulty: 7
Uploaded By:
[ROI 2019] 考古 (Day 2)
题目背景
翻译自 ROI 2019 D2T4。
三〇一九年,在对古城市 Innopolis 进行挖掘时,考古学家发现了一件古代遗物——一个硬盘,里面存有一个文件,据推测,该文件包含了所有 ROI 题目的文本。
经过对文件的研究,发现其中的信息被编码成了一个由英文字母组成的字符串 。题目文本相当长,并且包含了许多重复的内容,因此文件以压缩形式存储在硬盘上。解压缩文件使用以下算法:
在解压缩过程中,将生成一个由小写英文字母组成的字符串 。初始时,字符串 为空。压缩文件包含 个块,必须按顺序处理每个块。每个块具有两种类型之一。
- 块
1 w,其中 是一个字符串。处理此类块时,在字符串 的末尾添加字符串 。 - 块
2 pos len,其中 和 是正整数。假设字符串 中的字符从 开始编号。处理此类块时,将字符串 中从位置 开始的 个连续字符依次添加到字符串 的末尾。如果 的值足够大,刚刚添加的一些字符可能会在处理同一块时再次使用。
题目描述
考古学家们决定统计一个算法在 ROI 中考察的次数。为此,他们构建了一个由小写英文字母组成的字符串 ,并希望找出这个字符串在解压缩后的字符串 中的出现次数。
如果长度为 的字符串 作为子串从位置 开始出现,那么从第 个字符开始的连续 个字符串将是字符串 。例如,字符串 aba 在字符串 ababaaba 中作为子串出现三次,分别从第 个字符开始。
请编写一个程序,确定给定字符串 在解压缩后的字符串 中出现的次数。
输入格式
第一行包含两个自然数 和 ,分别表示字符串 的长度和压缩文本中的块数。
第二行包含一个非空字符串 ,由小写英文字母组成。
接下来的 行,包含按照题目背景的格式给出的块的描述。
输出格式
输出一个整数,表示字符串 在文本中出现的次数。
3 4
aba
1 ab
2 1 3
2 3 3
2 1 8
6
提示
样例解释:
的解压缩过程是这样的:
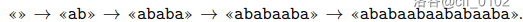
aba 在 ababaabaababaaba 中出现了 次。
数据范围:
设将前 块解压缩后字符串的长度为 ,第 块的类型为 。
| 子任务 | 分值 | 其它特殊性质 | |||
|---|---|---|---|---|---|
只含字母 a, |
|||||
只含字母 a |
|||||
对于 的数据,。